This is the first in (what I hope will be) a series of occasional postings. Targeted at developers mainly, these will cover some of the problems we come across, and how we solve them.
Chem4Word is about ten years old. It started out as a research project. Such projects typically explore new ways of solving problems. They don’t set out to optimize established approaches. When you keep adding new functions at the expense of making existing ones work better, you end up with cruft.
The cruftiest portion of Chem4Word was its in-memory chemistry handling. Chem4Word’s standard file format is Chemical Markup Language, an XML dialect. There was no logical differentiation between the file containing the information and its in-memory representation. The code simply loaded the CML as-is into an XDocument. It then manipulated the XML directly. This was very wasteful as it required the XML parsed every time we needed to manipulate something. XDocuments are fine for limited XML editing, but when you’re constantly hitting the document then the conversion overhead becomes huge.
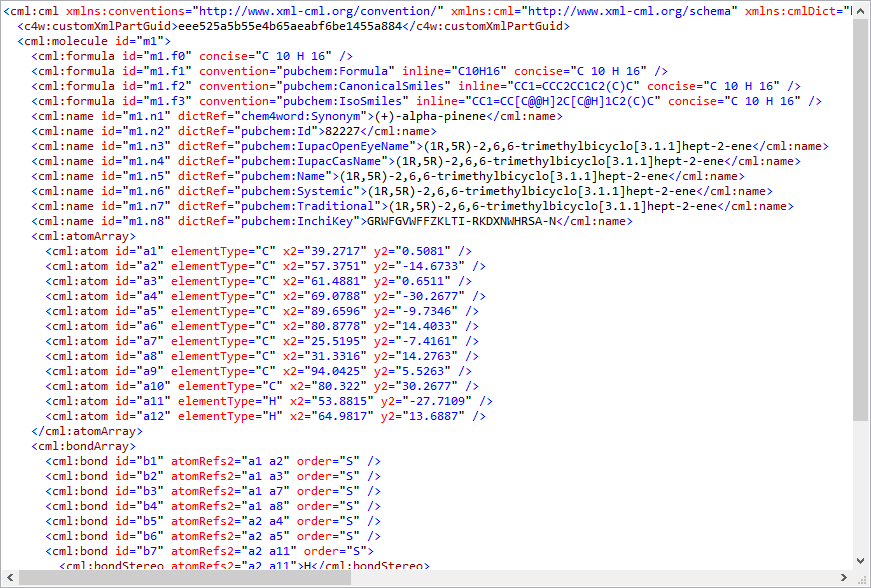
So, we wrote a completely new, in-memory Model class in C#. The Model in essence represents a chemical drawing. A Model contains Molecules, which can contain other Molecule objects or Atom and Bond collections.
Atoms obviously are the building blocks of Molecules. We store these in Molecules as dictionaries. These allow us to quickly retrieve an Atom by its label, such as ‘a1’. Bonds are simple collections, which reference a StartAtom and EndAtom as a text label. So Bond ‘b1’ would link Atoms ‘a1’ and ‘a2’, for example.
Atoms obviously have to reference a specific Element. There are obviously a limited number of these, stored in a single global PeriodicTable.
Each Molecule also contains what we term as emergent objects. So, a Molecule has a collection of Rings, and each Ring collects several Atoms. Atoms can be shared by more than one ring.
This simple approach allows us to create compact in-memory representations of quite complex molecules. The XML representation, instead of being central, is now relegated purely to persistence roles. Previewing, in-document rendering, editing and many other functions now work on the Model. A dedicated CMLConverter class handles conversion to and from the CML format, typically when storing this in a Custom XML Part.
No doubt some purists will take issue with this rather literal implementation but we (and you) are already reaping the benefits. The improved performance is by far the most dramatic effect. Even on a relatively fast machine, rendering insulin in the document used to take six or seven minutes. Now it takes a few seconds. We have seen performance improvements of 400-500% on small molecules and 12,000% on large ones!
One final benefit comes from exposing the atoms and bonds as objects in their own right, and organizing them as collections. We can now data-bind to them. Windows Presentation Foundation makes heavy use of data binding. So, we could theoretically data-bind various visual elements to their corresponding logical ones. And this is precisely what we do in the FlexDisplay component, which we will cover in a later post.